
新闻动态
news dynamic
news dynamic
发布日期:2026-03-26
3月23日,天津大学医疗机器人与智能系统研究院开展2026年第三期研究生阅读报告分享会,研究院2024级硕士陈思纯进行了题为《SurgVidLM:使用大语言模型实现多粒度手术视频理解》的报告分享。

当前多模态大语言模型(MLLMs)在医疗影像感知方面展现出巨大潜力,但仍存在以下问题:
(1)现有MLLMs多侧重于静态图像分析或视频的全局理解,难以捕捉手术过程中细微的“器械-组织交互”以及严格时间约束下的精细步骤;
(2)手术领域获取高质量且具备推理标注的视频数据集面临极大挑战,现有数据集常因访问受限或缺乏多粒度标注而难以支持深入研究。
为解决上述问题,香港中文大学团队以包含解剖识别、器械检测和工作流程识别等任务的手术场景理解为背景,构建出包含3.1万个视频-指令对的大规模数据集,并提出了SurgVidLM 模型。该数据集包含1800对完整视频问答对和29400对细粒度视频理解任务,通过一种新型的知识增强管线,将手术视频转化为包含摘要、关键步骤和叙述的三层级结构化表征,并涵盖了时间与感知的多维度推理任务。
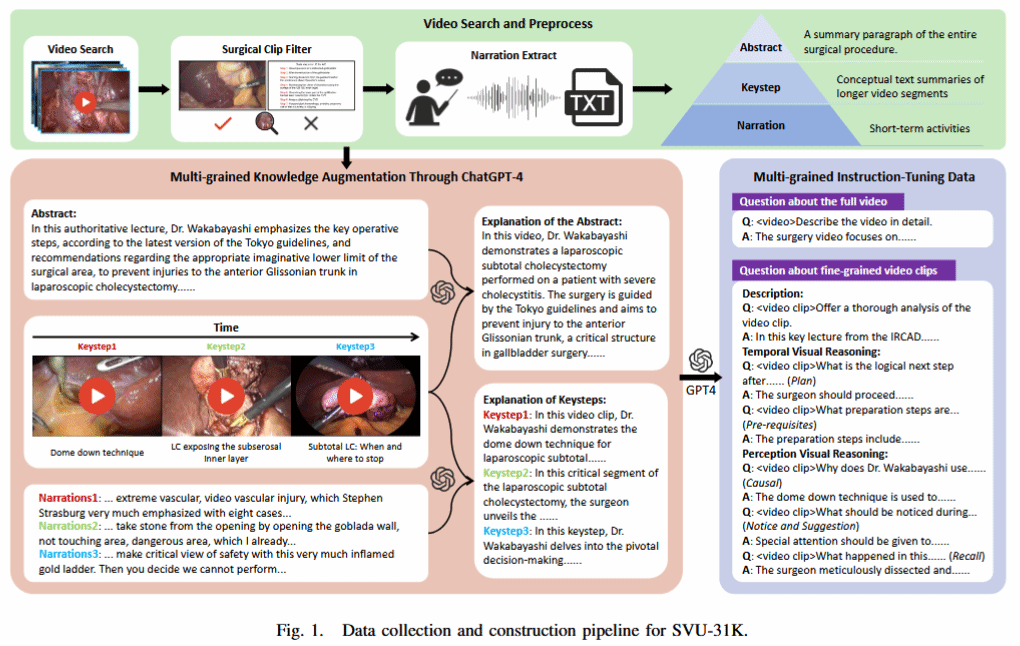
SVU-31K的数据收集与建设流程
SurgVidLM 模型作为首个专为机器人手术设计、支持全视频与精细视觉推理的多粒度视频语言模型,具有以下特点:
(1)引入StageFocus(阶段聚焦)机制,采用两阶段推理。第一阶段提取全局过程背景,第二阶段结合时间线索进行高频局部分析,引导模型从全局背景逐步深入到局部细节。
(2)为保留全局一致性,模型集成了MFA(多频率融合注意力)模块。该模块利用交叉注意力机制(Cross-Attention)将低频采样的全局上下文有效整合到高频采样的局部Token中,使模型同时关注宏观和细节语境。
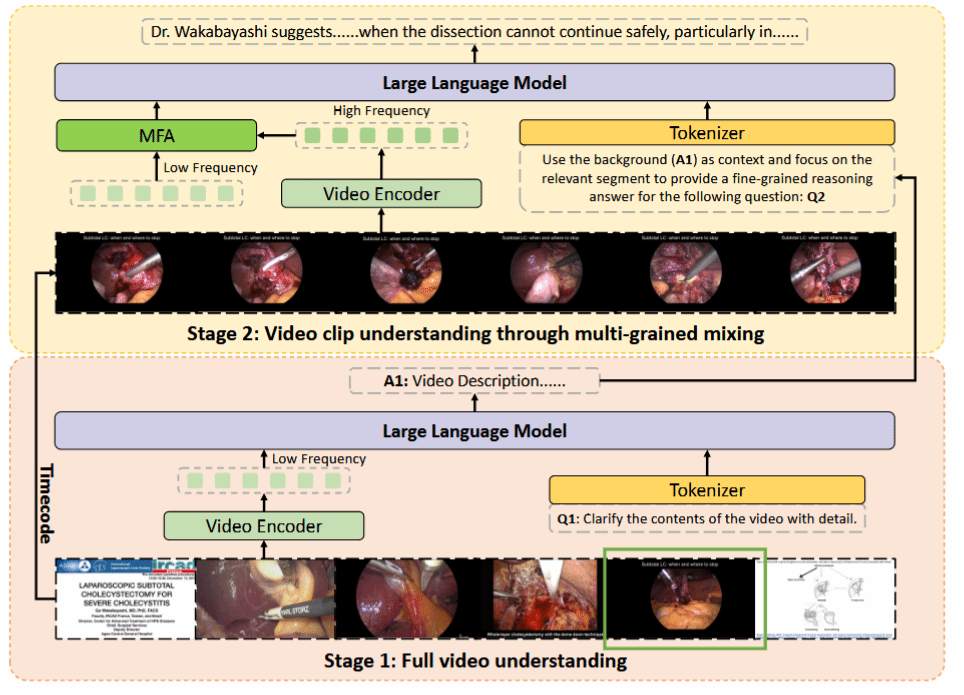
SurgVidLM模型架构
团队将此模型与Video-LLaVA,GroundingGPT,Video-LLaMA3,Qwen2-VL,Qwen2.5-VL等 SOTA 模型进行了对比实验。实验结果表明,SurgVidLM在信息正确性(CI)、细节导向(DO)、上下文理解(CU)、时间理解(TU)四个维度上均优于基线模型,并且在时间视觉推理和感知视觉推理任务中效果突出,证明了 MFA模块在对齐短时线索与长时背景方面的有效性。
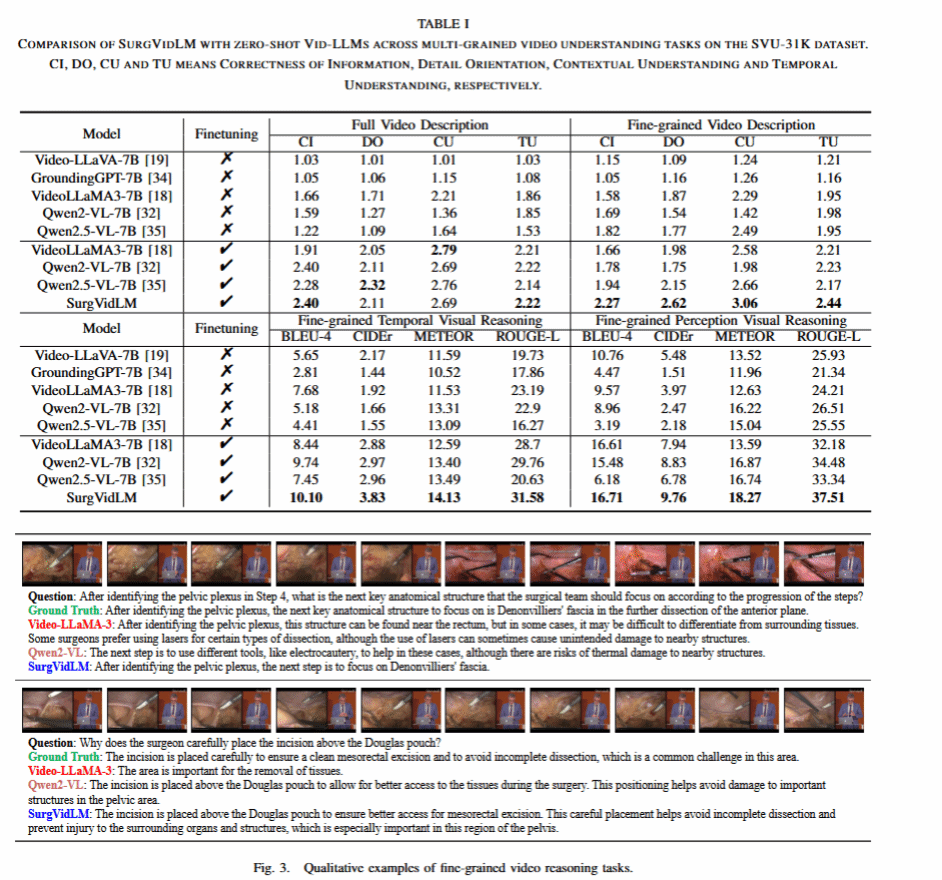
对比实验结果及细粒度视频推理任务示例
综上,SurgVidLM的学术贡献体现在:其构建的多粒度专用模型填补了研究空白,SVU-31K数据集解决了行业数据瓶颈,创新的StageFocus机制与多频融合注意力机制提供了新的技术思路,而充分的实验验证与场景拓展则为后续研究奠定了坚实基础。该研究不仅推动了手术视频理解领域的学术进步,也为多模态大语言模型与医疗场景的深度融合提供了新的研究视角与实践范式。
文献来源:
[1] Wang G, Wang J, Mo W, et al. SurgVidLM: Towards multi-grained surgical video understanding with large language model[EB].

