
新闻动态
news dynamic
news dynamic
发布日期:2026-03-13
3月9日,天津大学医疗机器人与智能系统研究院开展2026年第一期研究生阅读报告分享会,研究院2024级硕士张峰菩进行了题为《DINO-v3视觉大模型的技术优势及其在医学图像处理上的拓展应用》的报告分享。

DINOv3[1]为Meta AI团队在2025年发表的一款自监督视觉大模型,其方法具有以下的优势:
①patch token的理解单元设计实现了优秀的语义一致性,保证了token对同一物体识别的相似程度,提升了边界感知能力,使token在物体边界变化明显;
②自监督的训练不依赖对数据集的大量人工标注,模型可自主学习数量稀缺、模式复杂的手术数据集;
③backbone的特征提取,可通用于图像分割、阶段识别的多任务场景。

DINOv3提取的高分辨率密度特征
面向DINOv3的提出与方法优势,另一篇文章提出的SegDINO模型[2]将DINOv3的backbone率先迁移到手术场景下的轻量图像分割任务。采用DINOv3冻结的backbone预训练模型作为主干网络,提供高语义、结构化的patch-level特征;解码器上设计轻量化的L-Decoder,将多层token特征融合、上采样,进而输出二值分割掩码;使用BCE与Dice/IoU指标联合评估,进行监督训练。
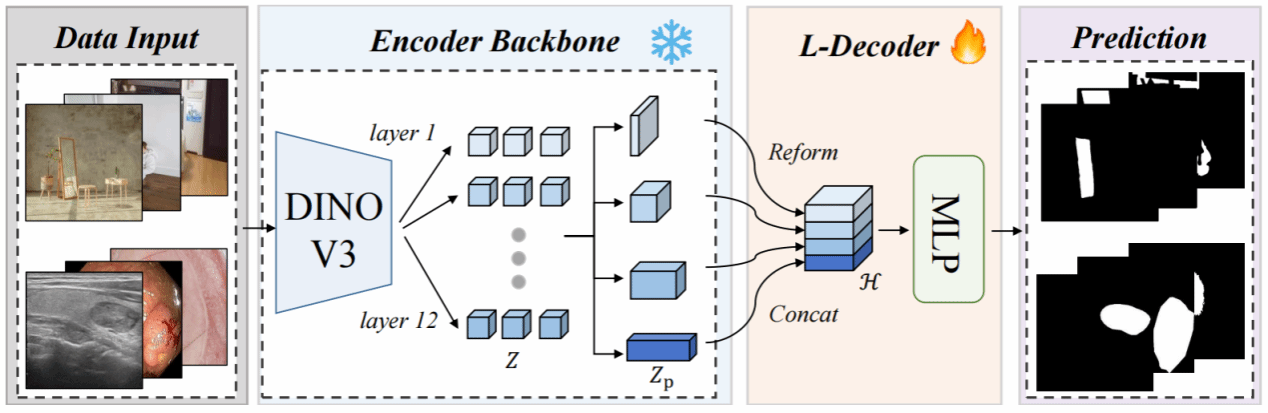
SegDINO模型架构
其主干网络上应用的DINOv3特征提取方法具有以下的技术特征:
①超大规模ViT架构:模型采用4096维度的embedding向量,适用于复杂医学图像的分割任务;
②RoPE(旋转位置编码):通过在提取特征时随机缩放坐标范围来提升尺度泛化能力,保证了模型在内窥镜图像场景下对不同的分辨率具有更好的适应性;
③Gram Anchoring:不直接约束每个 patch 的特征值,而是约束 patch 之间特征的二阶统计关系(即结构一致性),解决了训练时间变长后提取特征的质量降低和可能导致的局部语义崩塌,是此方法最突出的学术贡献。
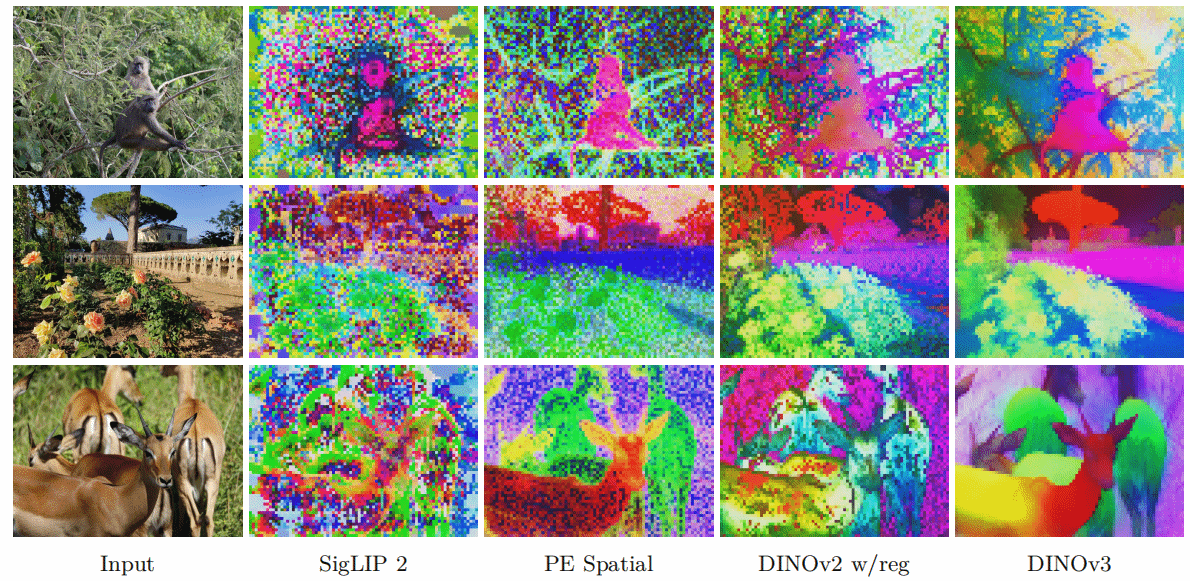
DINO-v3密度特征提取的对比
在实验设置上,文章在TN3K、Kvasir-SEG、ISIC三个医学图像数据集上做了训练和验证,与CNN-based segmentation models、传统ViT + decoder、DINOv2-based segmentation、SAM-based segmentation四个基线分割模型做了方法对比,得出的结论如下:
①DINOv3特征提取能力明显更优,特别是在医学图像场景下;
②轻量的解码器设计即可充分利用DINOv3提取的特征,可保证更优的模型性能/计算比;
③模型对高分辨率图像的处理效果更好,边界划分更清晰,并且对小目标的分割保持性也更优;
④模型在小数据量下的训练优势更大,泛化能力更好。
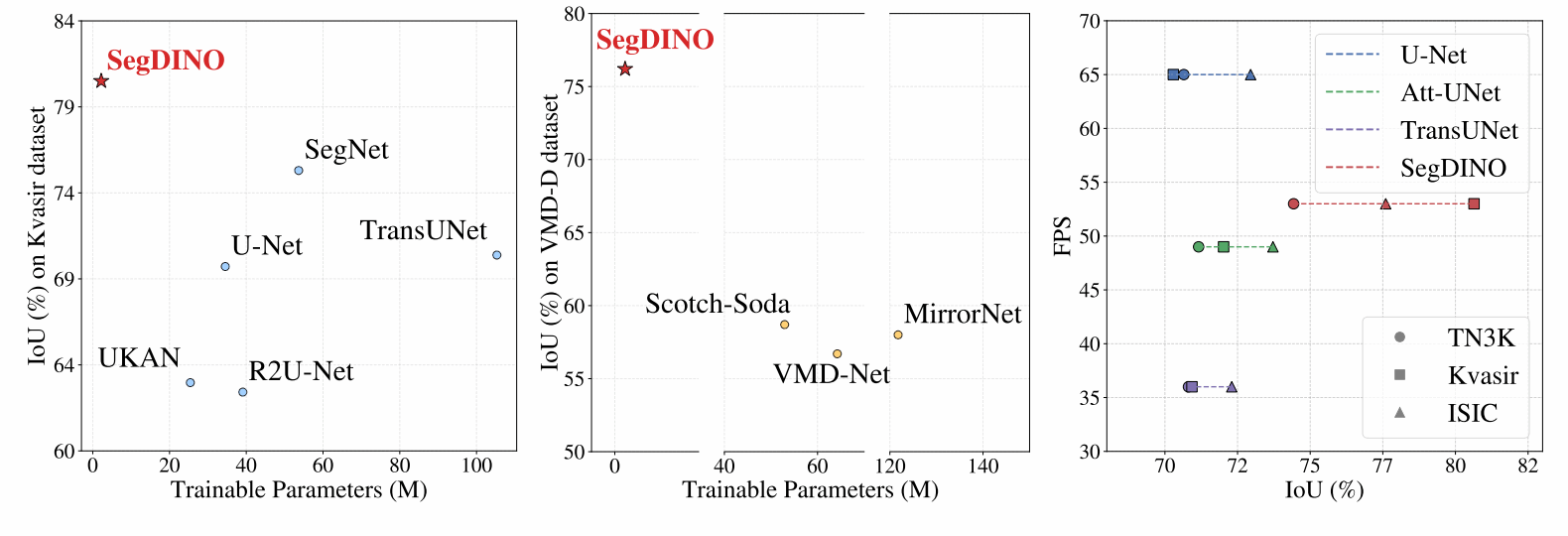
模型在不同数据集上的整体性能和效率
总体来看,当前DINOv3在医学图像处理上主要有以下两个优势:首先是多任务适用的backbone,在适用于器官、器械分割任务的同时具有在其他分类任务(如手术阶段、操作质量)上的拓展潜力,未来可实现联合术中识别任务;其次是自监督训练与高质量的特征提取,保证了模型对小数据量的样本友好性,以及更强的泛化能力。
文献来源:
[1] O. Siméoni. et al.,“DINOv3,” 2025, arXiv: 2508.10104.
发表机构/团队:Meta AI Research
[2] S. Yang. et al.,“SegDINO: An Efficient Design for Medical and Natural Images Segmentation with DINO-v3,”2025, arXiv: 2509.00833.

