
新闻动态
news dynamic
news dynamic
发布日期:2026-04-09
4月7日,天津大学医疗机器人与智能系统研究院开展2026年第五期研究生阅读报告分享会,5名研究生依次进行了阅读报告分享。
研究院2024级博士研究生史梓潭围绕《用于DIEP手术中穿支血管可视化的自主无标记增强现实技术》进行报告分享。

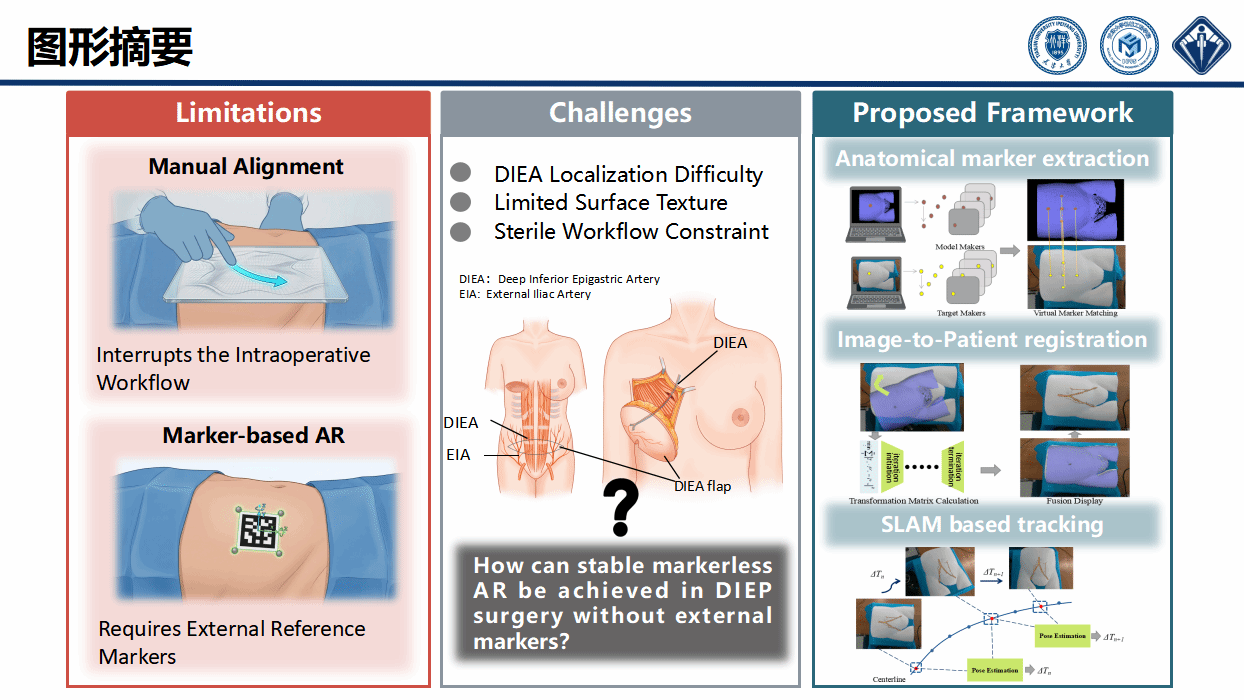
乳腺癌是女性中最常见的恶性肿瘤之一,传统治疗方式中多数患者需接受乳房切除术,严重影响其身体形象与心理健康。腹壁下深穿支(DIEP)皮瓣重建术作为新型治疗手段,已成为乳腺癌患者广泛采用的自体组织技术,其在美学效果与术后恢复方面具有显著优势。该术式需将患者腹部的DIEP皮瓣移植至胸部以重建乳房,主要挑战在于从腹壁识别并分离穿支血管。
目前,增强现实(AR)导航越来越多地用于DIEP手术,将模糊的解剖结构可视化,现有方法依赖于手动步骤和辅助设备,增加了手术风险。团队创新提出自主无标记的AR框架,通过基于视频的非接触式配准方法,提取腹部表面的生物特征并与虚拟模型进行匹配,无需物理标记物或外部定位装置即可实现术前血管模型与术中腹腔表面的对齐。同时,整合视觉特征追踪与基于SLAM的姿态估计技术,实现虚拟血管模型与手术野间的持续对齐。系统已进行体模实验及前瞻性临床评估验证,证实了其术中应用可行性及减轻外科医生工作负荷的潜力。
研究院2025级博士研究生文源浩进行了题为《阶段识别:少样本自适应与图引导优化策略》的报告分享。

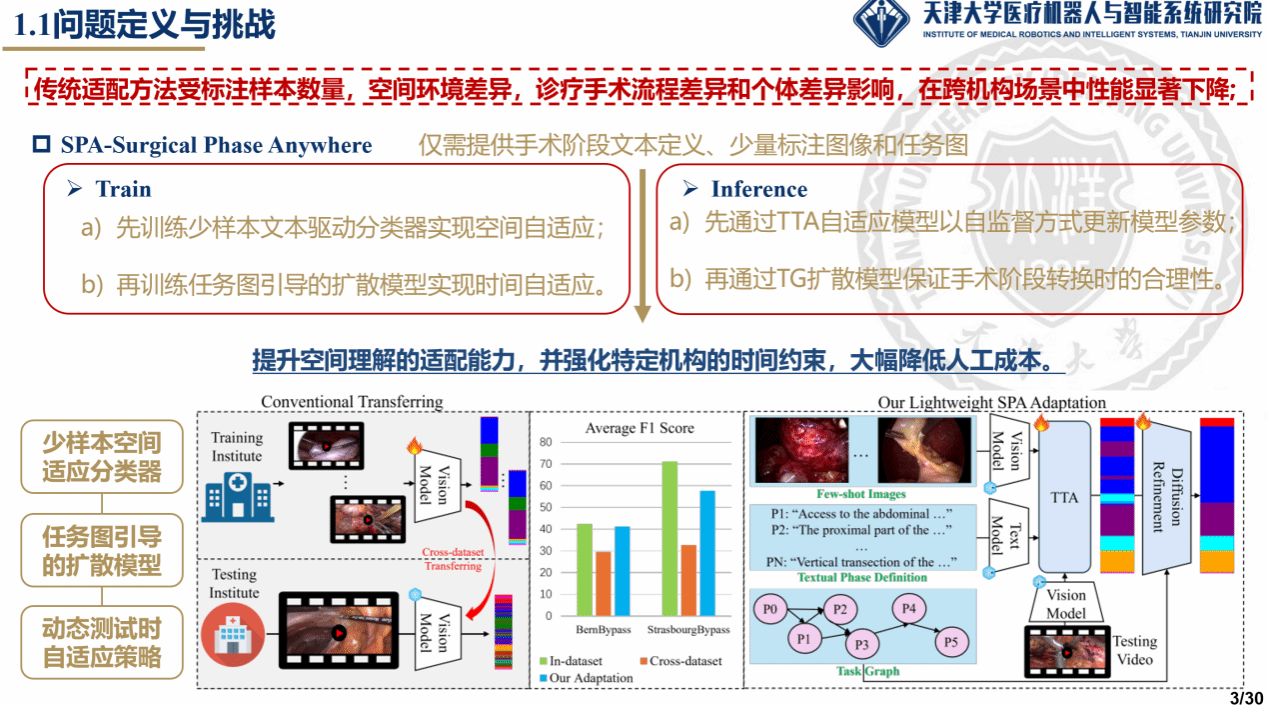
受异构手术室环境、机构诊疗规程以及解剖结构个体差异的影响,手术流程的复杂性与多样性为开发具备跨机构、跨术式泛化能力的手术理解模型带来了巨大挑战。基于大规模视觉—语言数据预训练的手术基础模型已展现出良好的迁移性,但其零样本性能仍受领域偏移的制约,难以在未见过的手术环境中发挥作用。
本文的核心在于针对目标医院只有极少量标注图像的情况,快速建立一个可用的手术阶段分类器。首先使用冻结的视觉编码器,将少量标注手术图像编码为图像特征,同时将每个手术阶段的文本定义编码为文本特征。在此基础上,作者构建出text-driven linear classifier(文本驱动的线性分类器),其核心思想是:每个类别的判别向量,不仅来自少量样本学习到的视觉原型,还融合了该类别对应的文本语义先验,最终达到“用少量图像学习目标域的视觉特征,同时用文本描述补充类别语义信息”的目的。该方法比纯视觉few-shot分类更稳健,更适合跨医院、跨场景的手术阶段识别。
研究院2024级硕士研究生徐一鸣围绕《用于加工未知表面薄壁零件的机器人柔顺控制框架:变形与姿态自适应》进行报告分享。

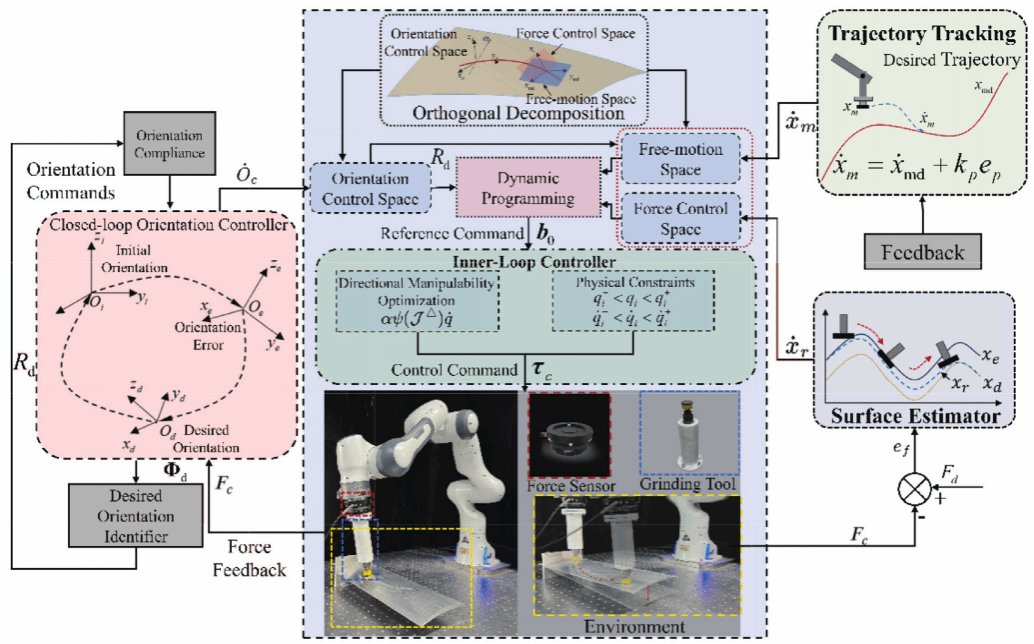
薄壁零件磨削加工中存在动态变形位姿和刚度多变以及轮廓不确定、在未知表面加工场景中适应性差、加工过程中力-姿态-运动的耦合关系导致控制精度不足等挑战。
为解决上述问题,研究人员构建了力-姿态-运动双环柔顺控制框架。首先将力与姿态进行切向与法向的正交化分解,再使用表面法向信息控制机器人力控制空间,最后通过检测是否存在耦合摩擦力对机器人姿态进行修正,使得安装在最末端的刀具轴线始终垂直于此时的表面切面。薄壁零件磨削加工与单孔腔镜机器人辅助手术中面临的远心不动点位姿修正、切口压力平衡等问题具有相似性,因此借鉴文献中正交化方法区分远心不动点错位情况,通过力误差积分计算切向错位、法向力误差识别法向错位的方向与幅值。结合切向信息,使手术开始前,单孔手术机器人的戳卡套筒的初始化位姿在理论远心不动点和皮肤表面法向偏角的允许误差范围内,实现远心不动点错位修正。
研究院2024级硕士研究生陈枫分享了论文《Cross-PCR: A Robust Cross-Source Point Cloud Registration Framework》。
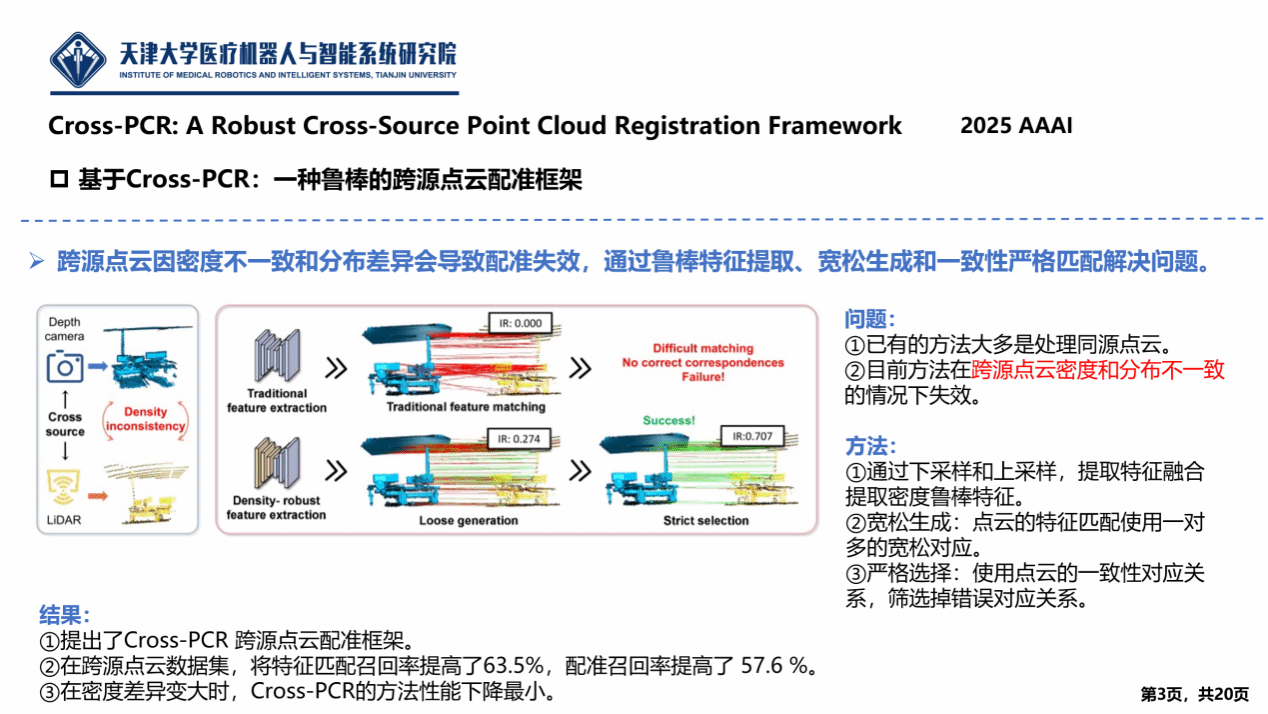
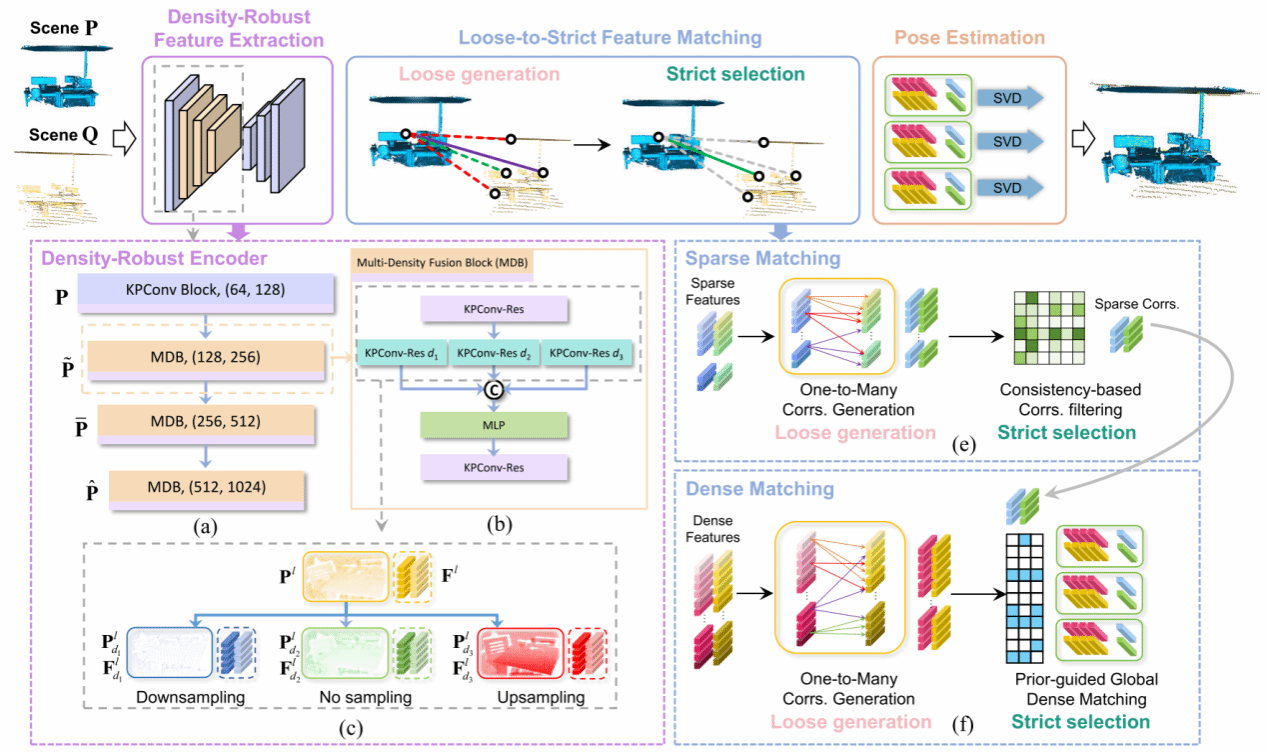
针对跨源点云因密度不一致和分布差异导致传统局部特征提取方法失效的问题,北京理工大学研究团队创新提出Cross-PCR框架。该方法设计了一种密度鲁棒编码器(DRE),通过多密度融合块(MDB)对稀疏源点云和稠密目标点云分别进行上采样、原采样和下采样,融合不同密度下的特征以提取密度不变的结构特征,有效解决了跨源数据的分布差异难题。
Cross-PCR采用“由松至严”(Loose-to-Strict)的两阶段匹配策略。首先在稀疏特征层面进行“一对多”的宽松生成,以捕获尽可能多的潜在正确对应关系;随后利用基于一致性的筛选机制剔除错误匹配。接着,利用筛选后的高质量稀疏对应关系作为先验,在稠密特征空间中进行全局密集匹配。实验结果表明,Cross-PCR在极具挑战性的跨源 3DCSR 数据集(特别是 Kinect-LiDAR 场景)上表现卓越,首次实现了室内的跨源鲁棒配准,特征匹配召回率提升了63.5个百分点,配准召回率提升了57.6个百分点。此外,该方法在3DMatch等同源数据集上也达到了SOTA性能,并在不同采样密度下保持了极强的鲁棒性。
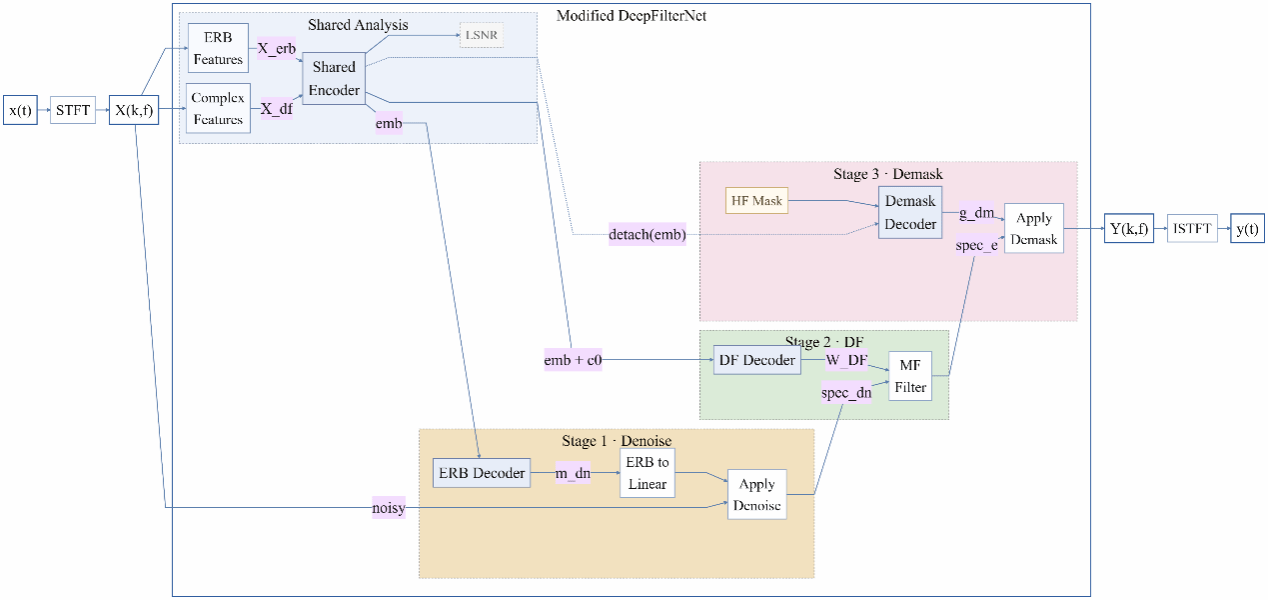
研究院2024级硕士研究生邱立进行了题为《持镜机器人语音增强策略与人智协同控制方式研究》的报告分享。

实时通信(RTC)系统对语音增强模型的核心要求是“因果性”,即模型推理时仅能利用当前及历史语音数据,无法访问未来信息,这一约束极大限制了RaD-Net2第一阶段语音修复任务的性能。为此,该文献引入“基于因果关系的知识蒸馏”策略以解决这一矛盾。训练阶段,构建非因果(Non-causal)修复网络的Teacher模型,可利用未来音频帧实现高精度失真修复;同时训练因果(Causal)修复网络的Student模型,让其在蒸馏过程中强制去模仿Teacher的输出。推理阶段,Student模型仍严格遵循因果约束,仅依赖历史信息,但其通过蒸馏学到的先验知识,能够精准“预测”并补全语音缺失成分,在保证低延迟的同时,最大化保留Teacher模型的修复性能,适配RTC场景需求。
文献来源:
[1] Yuan, K. et al. (2026). Recognizing Surgical Phases Anywhere: Few-Shot Test-Time Adaptation and Task-Graph Guided Refinement. In: Gee, J.C., et al. Medical Image Computing and Computer Assisted Intervention – MICCAI 2025. MICCAI 2025. Lecture Notes in Computer Science, vol 15968. Springer, Cham.
[2] Qi J , Hou Z , Deng Y ,et al.Prediction method of residual stress and deformation in belt grinding of thin-walled ring workpieces[J].Transactions of the Canadian Society for Mechanical Engineering, 2025,49(4):635-648.DOI:10.1139/tcsme-2024-0223.
[3] Zhao G, Guo Z, Du Z, et al. Cross-PCR: A robust cross-source point cloud registration framework[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2025, 39(10): 10403-10411.
[4] Liu M, Chen Z, Yan X, et al. RaD-Net 2: A causal two-stage repairing and denoising speech enhancement network with knowledge distillation and complex axial self-attention[J]. arXiv preprint arXiv:2406.07498, 2024.

